

Firms that want on-line transactions can’t afford server breakdowns. In consequence, these companies search methods to create a failsafe process that retains their information secure even when the server collapses. One such technique is failover clustering.
Failover clustering could be ruled by managed area title system (DNS) supplier options; nonetheless, understanding its mechanism and key options will help restrict any failover challenges.
What’s failover clustering?
Failover clustering operates on a gaggle of laptop servers to guarantee excessive availability (HA) or steady availability (CA) for server functions. This expertise ensures that if one server or node fails, one other cluster node stands able to take up the workload with out disruption.
This method retains your server workloads scalable and out there. Many main server packages, reminiscent of Microsoft Change, Microsoft SQL Server, and Hyper-V, depend on failover clustering to guard themselves.
Some failover clusters make use of bodily servers, whereas others use digital machines (VMs). Everybody selects the type of cluster they want primarily based on the necessities of their server software.
A cluster consists of two or extra nodes that alternate information and software program to be processed by means of bodily cables or a specialised safe community. Clustering expertise of a number of sorts can be utilized for load balancing, storage, and concurrent or parallel computing. In some situations, failover clusters are mixed with further clustering applied sciences.
A failover cluster’s main operate is to offer CA or HA for functions and companies. CA clusters, also referred to as failure tolerant (FT) clusters, let end-users proceed utilizing functions and companies even when a server fails. You may see a short interruption in service brought on by HA clusters, however the system can get better with no information loss and little downtime.
Why is failover clustering vital?
With failover clustering, you possibly can restore inactive nodes with out shutting down your database, avoiding downtime issues whereas rapidly repairing damaged servers. Moreover, within the occasion of a {hardware} failure, this method terminates the database to guard the energetic nodes.
Failover clustering additionally automates information restoration within the occasion of a failure. This reduces your reliance on the data expertise (IT) crew and permits your servers to get better rapidly. It additionally delivers glorious structured question language (SQL) cluster availability with minimal downtime. The automated failover performance of failover clustering preserves the operate of your database, even when there’s a {hardware} breakdown.
How do failover clusters work?
Failover clustering consists of two basic processes, HA and CA, for server functions.
Whereas CA failover clusters attempt to attain 100% availability, HA clusters attempt for 99.999%, generally often called 5 nines. This downtime totals not more than 5.26 minutes annually. CA clusters have increased availability however require extra {hardware} to function, growing their total price.
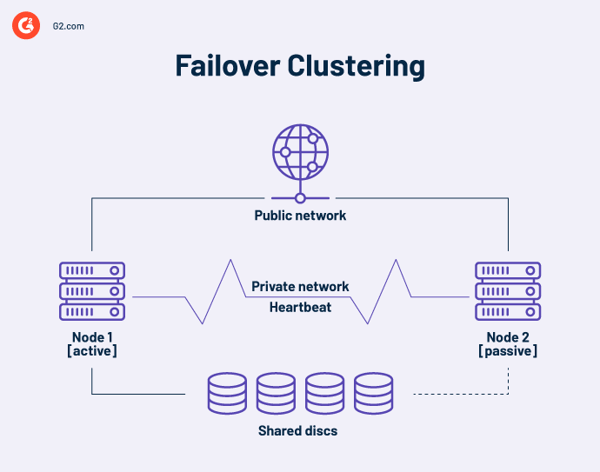
Excessive availability failover clusters
A excessive availability cluster is a set of unbiased computer systems that share assets and information. A failover cluster’s nodes have entry to shared storage. A monitoring hyperlink can also be included in high-availability clusters to test the opposite servers’ heartbeat or well being. A heartbeat is a non-public community shared solely by the nodes within the cluster. It’s not accessible from the skin.
At any level, no less than one node in a cluster is energetic, and no less than one is dormant or passive.
In a fundamental two-node association, if Node 1 fails, Node 2 acknowledges the failure through the heartbeat connection and configures itself because the energetic node. Clustering software program on every node ensures purchasers hook up with an energetic node.
Bigger installations might make use of devoted servers to manage the cluster. A cluster administration server at all times sends heartbeat indicators to establish any nodes failing and, in that case, to inform one other node to take up the work.
Some cluster administration software program instruments deal with HA for VMs by grouping the machines and servers right into a cluster. If a number fails, a unique host resumes the VMs.
As a potential single failure level, shared storage represents a danger. Nonetheless, combining a redundant array of unbiased disks 6 and 10 – aka RAID 6 and RAID 10 – will help keep service even when two exhausting drives fail.
Electrical energy is likely to be one other single level of failure if all servers are related to the identical grid. Offering every node with its personal uninterruptible energy provide (UPS) retains them protected.
Steady availability failover clusters
In contrast to the HA paradigm, a fault-tolerant cluster contains quite a few computer systems that share a single copy of a pc’s working system (OS). Software program instructions given to at least one system are additionally executed on the opposite programs.
CA insists that the group employs formatted laptop gear and a backup UPS. CA wants a always accessible and virtually good reproduction of the bodily or digital system operating the service. This redundancy mannequin is named 2N.
CA programs can compensate for a variety of faults. A fault-tolerant system might establish a malfunction of:
- A tough disk drive
- A processing unit in a pc
- A subsystem for enter and output (I/O)
- An influence supply
- A part of a community
The failure level could also be found promptly, and a backup part or technique can take its place instantly with out disrupting the following service.
Clustering software program can join two or extra servers to behave as a single digital server or assemble varied different CA failover cluster configurations. For example, if one of many digital servers fails, the others reply by briefly eradicating the digital server from the cluster quorum. The digital server then redistributes the burden throughout the opposite servers till the crashed server is able to restart.
A double {hardware} server with all bodily elements replicated is a substitute for CA failover clusters. They compute individually and concurrently on varied {hardware} platforms and synchronize utilizing a devoted node that screens the outcomes from each bodily servers. Whereas this resolution supplies safety, it could be costlier.
Failover clustering options
Many organizations use failover clustering for mission-critical functions. It is because the next traits make failover clustering a big approach.
- Scalability: As a result of failover clustering is predicated on a gaggle of clusters collaborating to stop server failure, you possibly can simply and readily scale as wanted by including new clusters.
- Stability: Clustered servers join by means of wires. The remaining clusters can nonetheless supply service even when a number of fail because of exterior elements.
- Actual-time monitoring: The cluster nodes are always monitored to verify they work correctly. When a cluster will get restarted or transferred onto one other node.
- Cluster shared quantity (CSV): This characteristic supplies a constant and distributed namespace for nodes to make use of whereas working with shared storage. It’s essential to maintain server functions operating with out interruption from begin to end.
Varieties of failover clusters
Vital developments in failover clustering have occurred within the final decade, with many organizations now providing their very own model of clustering options. A few of the most typical cluster companies are detailed right here.
VMware failover clusters
VMware supplies quite a few virtualization applied sciences for VM clusters. The vSphere vMotion’s CA structure exactly duplicates a VMware digital machine and its community between bodily information middle networks.
VMware vSphere HA, a second product, supplies HA for VMs by grouping them and their hosts right into a cluster for automated failover. Moreover, this system doesn’t depend on exterior elements reminiscent of DNS, which lowers potential factors of failure.
Home windows server failover cluster
The Home windows server failover cluster (WSFC) technique fosters the creation of Hyper-V failover servers. Between 2016 and 2019, this technique grew fashionable amongst Microsoft Home windows customers. WSFC permits cluster monitoring and affords the required failover mechanism robotically. Within the occasion of a server loss, WFSC strikes the clusters to a separate node or makes an attempt to restart them. Moreover, its CSV expertise supplies a distributed namespace that enables a number of nodes to share reminiscence.
SQL server
This Microsoft product, launched with SQL Server 2017, has sturdy HA options that use WSFC expertise. SQL server elements are thought-about WSFC cluster assets on this context. They’re additional built-in with different WSFC-dependent assets. In consequence, WSFC has authority over figuring out and speaking orders to restart a SQL server occasion or to maneuver situations like these to a brand new node.
Pink Hat Linux
Apart from Microsoft, different working system distributors include their very own failover cluster options. For instance, Pink Hat Enterprise Linux (RHEL) followers can use the HA extension and Pink Hat International File System (GFS/GFS2) to ascertain HA failover clusters. Single-cluster stretch clusters spanning many places and multi-site, disaster-tolerant clusters are supported. Storage space community (SAN) information storage replication is often utilized in multi-site clusters.
Functions of failover clustering
This sturdy mechanism facilitates the next real-time functions.
Availability of mission-critical functions.
On-line transaction processing (OLTP) computer systems should have fault-resistant programs. OLTP, which requires full availability, is used for airline reservation programs, digital inventory buying and selling, and ATM banking.
Many industries, reminiscent of manufacturing, delivery, and retail, make use of CA clusters or failure-resistant computer systems for mission-important functions. E-commerce, order administration, and employees time clock programs rely as examples.
Excessive availability clusters are sometimes acceptable for clustering functions and companies that require solely five-nines uptime.
Catastrophe reduction
Catastrophe restoration additionally advantages from failover clustering. It’s strongly really useful that failover servers be hosted at distant websites as a result of a calamity reminiscent of a fireplace or flood destroys all bodily {hardware} and software program.
Storage Duplicate, a expertise that duplicates volumes between servers for catastrophe restoration, is included in Home windows Server 2016 and 2019. Stretch failover is a expertise characteristic that lets failover clusters span two places.
Organizations can replicate information over varied facilities by extending failover clusters. If tragedy strikes at one location, all information is preserved on failover servers on the others.
Replication of a database
In response to Microsoft, the WSFC was first launched in Home windows Server 2016 to safeguard “mission-critical” companies, like its SQL server database and Microsoft Change communications server.
For database replication, different distributors provide failover cluster expertise. For instance, MySQL Cluster has a heartbeat technique that allows quick failure detection to different nodes within the cluster, typically in below a literal second, with no service disruptions to purchasers.
Databases could also be replicated to faraway websites utilizing the geographic replication functionality.
Advantages of failover clusters
The thought of failover clusters is to make sure that customers expertise minimal disruptions in service. Nonetheless, different extra advantages of failover clustering are mentioned beneath.
- Elevated useful resource availability: If one clever server fails, the others within the cluster choose up the burden. This protects essential time and knowledge.
- Strategic useful resource allocation: You get to distribute tasks between nodes in no matter manner you select. This minimizes overhead since not all computer systems are required to execute all tasks concurrently, supplying you with a manner to make use of your assets extra freely.
- Elevated processing energy: Extra machines, extra energy.
- Better scalability: As your person base and report complexity increase, so can your assets.
- Simplified administration: Clustering makes dealing with vital or quick-changing programs simpler.
Limitations of failover clustering
As vital as failover clustering is, it comes up in opposition to the next limitations.
- Complicated configurations: Failover clustering configuration for Home windows requires you to deal with many networks and community playing cards directly. In consequence, deploying this technique is troublesome, particularly for inexperienced persons.
- Instrument integrations: Home windows failover clustering and Hyper-V have to be extra carefully built-in. You need to modify every of them to finish failover clustering efficiently.
- Internet interface: There’s no net interface to regulate cluster parameters. To entry the cluster supervisor characteristic, it’s essential to manually log in to a distant desktop.
Failover clustering options: managed DNS suppliers
By working along side failover clustering programs, managed DNS suppliers redirect visitors to alternate servers or information facilities throughout failover occasions, making certain uninterrupted entry to your companies so that you obtain excessive availability and decrease downtime.
High 5 managed DNS suppliers:
* Above are the highest 5 main managed DNS suppliers software program from G2’s Fall 2023 Grid® Report.

{kind=link}
Modernizing reliability
Failover clustering has emerged as a dependable and important possibility for top availability and fault tolerance inside present IT infrastructures. It supplies ongoing operations regardless of {hardware} failures or scheduled upkeep by robotically spreading workloads and assets throughout quite a few networked nodes. This expertise provides you one other solution to deal with an important facet of what you are promoting – making every buyer’s expertise secure and comfortable.
Fortifying your system’s resilience doesn’t damage, both!
Get began with a information to DNS safety for a strong system technique.